PHPで文字列操作を行うための主な関数を紹介します。文字列操作には正規表現の知識も必要になるので、正規表現の基礎についても解説します。
目次
文字列操作関数
strlen
( 文字列の長さを取得 )
// 書式
int strlen ( string $string )
// 戻り値
string のバイト数$str = "abcde";
echo strlen($str); // 5
$str = "あいうえお";
echo strlen($str); // 15(内部エンコードがUTF-8の場合)strcmp
( 文字列の比較 )
// 書式
int strcmp ( string $str1 , string $str2 )
// 戻り値
等しければ 0$str1 = "あいう";
$str2 = "あいうえ";
echo strcmp($str1, $str2); // -3(内部エンコードがUTF-8の場合)
echo "<br>";
$str1 = "あいうえお";
$str2 = "あいう";
echo strcmp($str1, $str2); // 6(内部エンコードがUTF-8の場合)
$str1 = "あいう";
$str2 = "あいう";
echo strcmp($str1, $str2); // 0類似関数
| 関数 | 概要 |
|---|---|
| strcasecmp | 大文字小文字区別しないで比較。 |
| strncmp | 比較する文字数を指定できる。 |
| strncasecmp | 比較する文字数を指定できる。大文字小文字を区別しないで比較。 |
implode
( 配列要素の連結 )
// 書式
string implode ( string $glue , array $pieces )
// 戻り値
各配列要素間に glue 文字列をはさんで連結した文字列echo implode(",", array("山田", "鈴木", "佐藤")); // "山田,鈴木,佐藤"explode
( 文字列を分割 )
// 書式
array explode ( string $delimiter , string $string [, int $limit ] )
// 戻り値
string の内容を delimiter で分割した文字列の配列$str = "山田,鈴木,佐藤";
$array = explode(",", $str);
var_dump($array);
//array (size=3)
// 0 => string '山田' (length=6)
// 1 => string '鈴木' (length=6)
// 2 => string '佐藤' (length=6)substr
( 文字列の一部分を抽出 )
// 書式
string substr ( string $string , int $start [, int $length ] )
// 戻り値
抽出した文字列。失敗した場合に FALSEecho substr('abcdef', 1); // bcdef
echo substr('abcdef', 1, 3); // bcd
echo substr('abcdef', -4); // cdef
echo substr('abcdef', -3, 2); // deマルチバイト対応したい場合、mb_substrを利用します。
trim
( 先頭と末尾にある空白を取り除く )
文字列の先頭と末尾にある空白、もしくは指定文字を取り除きます。
// 書式
string trim ( string $str [, string $character_mask = ” \t\n\r\0\x0B” ] )
// 戻り値
取り除いたあとの文字列echo trim(" abc "); // "abc"
echo trim("$[abc]$", "$[]"); // "abc"類似関数
| 関数 | 概要 |
|---|---|
| ltrim | 文字列の先頭ある空白、もしくは指定文字を取り除く |
| rtrim | 文字列の末尾にある空白、もしくは指定文字を取り除く |
strpos
( 文字列探索 )
// 書式
mixed strpos ( string $haystack , mixed $needle [, int $offset = 0 ] )
// 戻り値
指定文字が見つかった位置。見つからない場合はFALSE。$str1 = "あいうえお";
$str2 = "う";
if (strpos($str1, $str2) !== false) {
echo "「" . $str1 . "」には「" . $str2 . "」が含まれています";
}preg_match
( 正規表現で文字列探索 )
// 書式
int preg_match ( string $pattern , string $subject [, array &$matches [, int $flags = 0 [, int $offset = 0 ]]] )
// 戻り値
マッチした場合は 1、マッチしなかった場合は 0、エラーが発生した場合は、FALSE。if (preg_match("/^[a-zA-Z0-9]+$/", $data)) {
// 英数字の場合
}
if (preg_match("/tanaka/i", "He is TANAKA")) {
// tanakaという文字列を含んでいる場合(大文字小文字を区別しない)";
}
if (preg_match("/^http*/", "http://localhost/")) {
// 先頭がhttpで始まる場合
}
if (preg_match("/^[0-9]{2,4}-[0-9]{2,4}-[0-9]{3,4}$/", $data)) {
// 電話番号の形式の場合
}preg_match_all
( 繰り返し正規表現で文字列探索 )
// 書式
int preg_match_all ( string $pattern , string $subject [, array &$matches [, int $flags = PREG_PATTERN_ORDER [, int $offset = 0 ]]] )
// 戻り値
パターンがマッチした総数(0となる可能性あり)。エラーが発生した場合は、FALSE。$data = "3412342123";
if (preg_match_all("/123/", $data, $matches)) {
var_dump($matches);
//array (size=1)
// 0 =>
// array (size=2)
// 0 => string '123' (length=3)
// 1 => string '123' (length=3)
}strstr
( 指定文字以降の文字列を取得 )
// 書式
string strstr ( string $haystack , mixed $needle [, bool $before_needle = false ] )
// 戻り値
部分文字列。見つからなければFALSE。$email = 'XXXXXXXX@YYYYYYYY';
$domain = strstr($email, '@');
echo $domain; // @YYYYYYYY
$user = strstr($email, '@', true);
echo $user; // XXXXXXXXstr_replace
( 文字列置換 )
// 書式
mixed str_replace ( mixed $search , mixed $replace , mixed $subject [, int &$count ] )
// 戻り値
置換後の文字列$str = "とうきょうと";
echo str_replace('と', 'ああ', $str); // "ああうきょうああ"
echo str_replace('と', '', $str); // "うきょう"preg_replace
( 文字列置換[正規表現] )
// 書式
mixed preg_replace ( mixed $pattern , mixed $replacement , mixed $subject [, int $limit = -1 [, int &$count ]] )
// 戻り値
置換後の文字列echo preg_replace("/(\d{4})\/(\d{2})\/(\d{2})/", "$3/$2/$1", "2015/06/14"); // "14/06/2015"sprintf
( フォーマット )
// 書式
string sprintf ( string $format [, mixed $args [, mixed $… ]] )
// 戻り値
フォーマットされた文字列$year = 2015;
$month = 5;
$day = 11;
echo sprintf("%04d年%02d月%02d日", $year, $month, $day ); // "2015年05月11日"
$str = "2015";
echo sprintf( "%010s", $str); // "0000002015"正規表現の書き方
特殊文字など
| 記号 | 説明 |
|---|---|
. | 改行以外の1文字 |
^ | 行頭 |
$ | 行末 |
\| | いずれかの文字列 |
() | グループ化 |
\\ | 直後のメタ文字をエスケープ |
[abc] | a,b,cいずれかの1文字 |
[^abc] | a,b,c以外の1文字 |
[a-zA-Z0-9] | 英数字 |
\d | [0-9]と同じ |
\D | [^0-9]と同じ |
\s | 空白1文字 |
\S | 空白以外1文字 |
\n | 改行 |
\t | タブ |
直前文字の繰り返し指定
| 記号 | 説明 |
|---|---|
* | 0回以上の繰り返し |
+ | 1回以上の繰り返し |
? | 0回または1回の出現 |
{n} | n回の繰り返し |
{n,m} | n回以上、m回以下の繰り返し |
{n,} | n回以上の繰り返し |
パターン修飾子
| 記号 | 説明 |
|---|---|
i | 大文字小文字を区別しない |
s | シングルラインモードにする(.が改行にマッチする) |
u | パターン文字列をUTF-8として処理 |
例
// 電話番号であるか(ハイフン付き)
/^[0-9]{2,4}-[0-9]{2,4}-[0-9]{3,4}$/
// 郵便番号であるか(ハイフン付き)
/^[0-9]{3}-[0-9]{4}$/
// 0:00~23:59の範囲であるか
/^([0-9]|[1][0-9]|[2][0-3]):[0-5][0-9]$/複数マッチする場合
マッチした箇所を全て返す関数ではなく、1つだけ返す関数を利用した場合、複数箇所でマッチする箇所があるときには、最も左にある箇所が返されます。
最小量指定子と最大量指定子
マッチする範囲を最大にすることを最大量指定子といい、最小にすることを最小量指定子といいます。デフォルトは、最大量指定子で判定します。
例を挙げます。HTMLのタグで囲まれた部分だけマッチさせたいとします。
この時、下記のように指定すると最大量指定子のため全文字列がマッチしてしまいます。
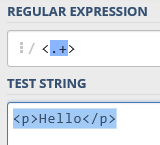
?をつけると最小量指定子になります。結果も以下のようになります。
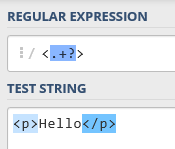
今回の例ですと以下のようにしてもタグを取得できます。








