DynamoDBのデータをData Pipelineを利用してエクスポート、インポートする方法を確認します。
利用するAWSリソース
- Data Pipeline
- ワークフローを管理
- S3
- Exportデータの格納先
- EMR
- 分散処理フレームワーク
- 1台の
マスターノードがコアノードタスクノードにジョブを振り分ける HadoopApache SparkPrestoなどの分散処理アプリケーションをサポート
前準備
IAM Roleの作成
下記2つのIAM Roleを作成しておきます。
DataPipelineDefaultRole- 「Data Pipeline」および「Data Pipeline管理のEMRクラスター」を呼び出すことを許可
DataPipelineDefaultResourceRole- 「Data Pipelineが起動するEC2インスタンス」に対して「S3」「DynamoDB」などのサービスへのアクセスを許可
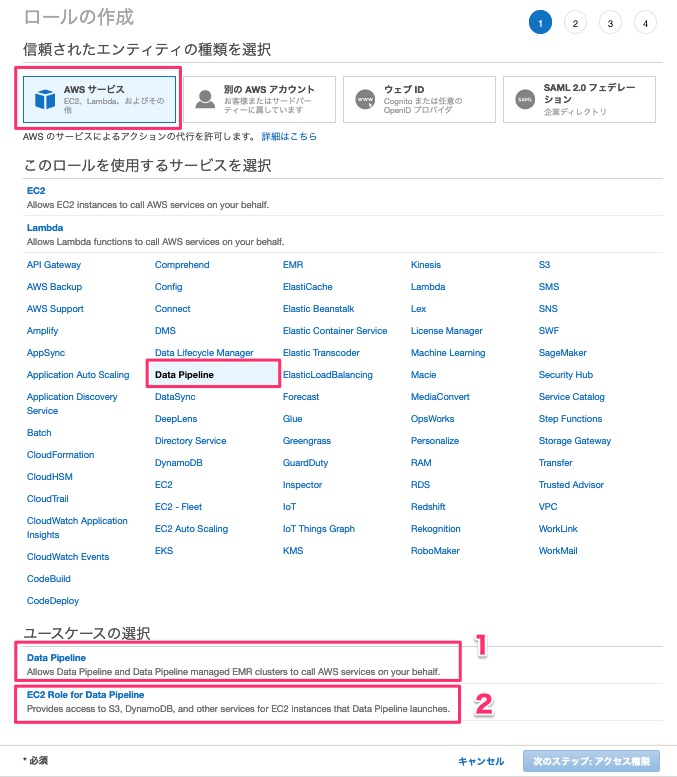
DataPipelineDefaultRoleでは1を選択。
DataPipelineDefaultResourceRoleでは2を選択。
2つのIAMロールを作成しました。

S3バケットの作成
Export先のS3バケットを作成しておきます。
ここでは例として dynamodb-export-wakuwaku-sample というバケットを作成しました。
Export
パイプラインの設定

Data Pipelineの管理画面を開き、Get started nowをクリックします。
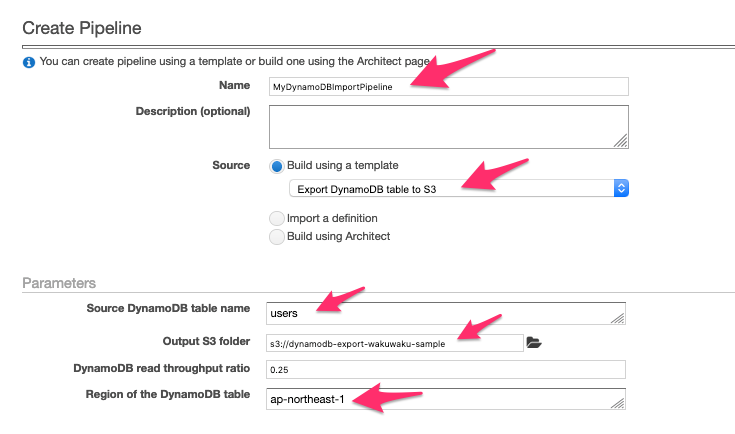
Nameにパイプラインの名前を入力します。
SourceにExport DynamoDB table to S3を指定します。
Source DynamoDB table nameにエクスポートしたいテーブル名を指定します。
Output S3 folderにエクスポート先となるS3バケットを指定します。
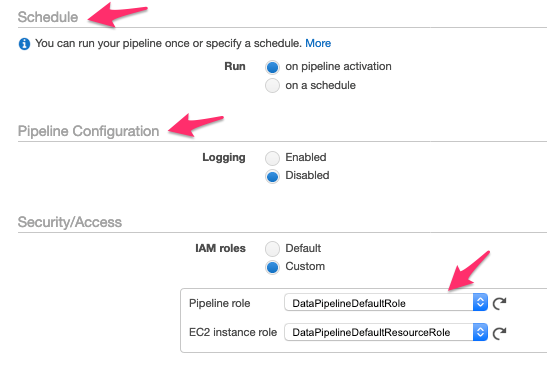
Schedule
今回、スケジューリング設定はしませんが、ここで設定しておくことができます。
Pipeline Configuration
今回、ログ出力はしませんが、トラブル対応としてログ出力しておいたほうが安心です。
Security/Access
先ほど作成したIAMロールを選択しています。
設定が完了したらAcrivateをクリックします。
パイプラインの生成完了 & 実行
パイプラインが生成されました。

Data PipelineのStatusについては下記ページにて確認できます。
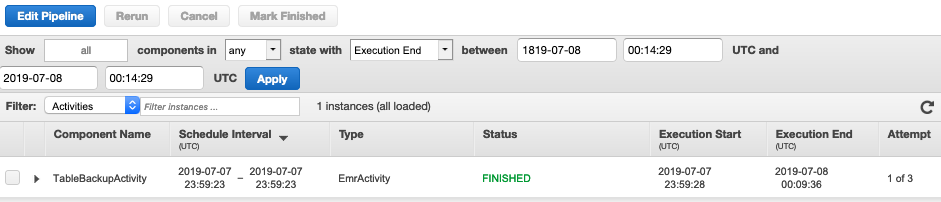
パイプラインの実行完了
エクスポート処理が完了しました。今回、DynamoDBのデータ量は5項目しかなかったのですが、全体の処理に10分ほど時間がかかりました。
以下のようにS3にエクスポートされました。
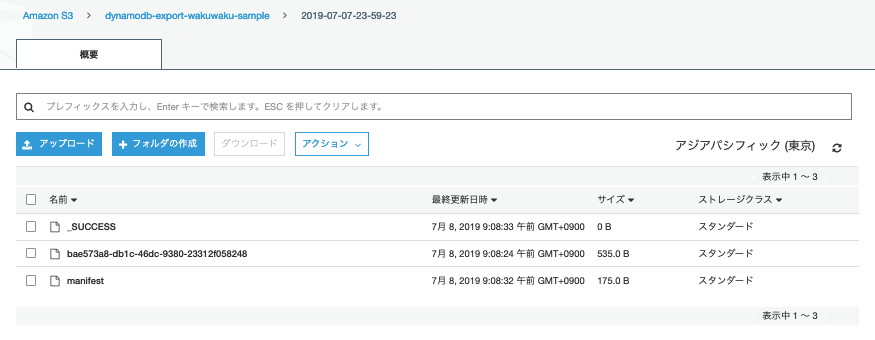
Import
Import先のDynamoDBテーブル作成
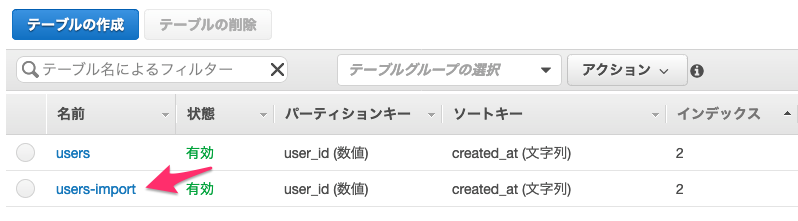
Import先のDynamoDBテーブルを作っておく必要があります(キースキーマは同じにする)。
ここでは、users-importというテーブルを作成しました。
パイプラインの設定
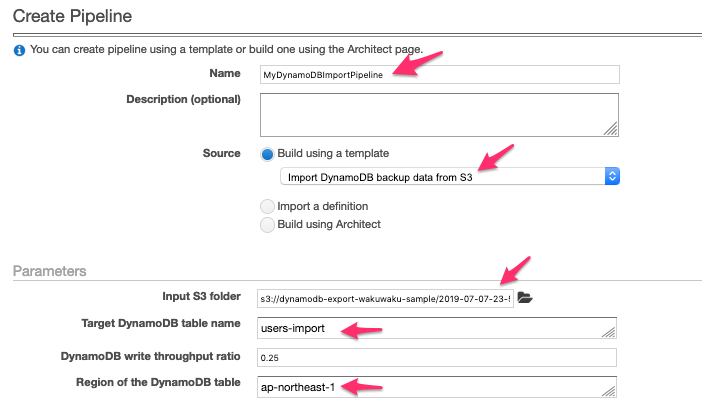
Nameにパイプラインの名前を入力します。
SourceにImport DynamoDB backup data from S3を指定します。
Target DynamoDB table nameにインポート先のテーブル名を指定します。
Input S3 folderにインポート元となるS3バケットのFolderを指定します。
その他はExportのときと同じ設定で、Acrivateをクリックすると、users-importにデータがimportされます。







